GTC2016にて、Facebookが新たなAI研究の一環として、ニューラルネットワークによるテキスト文からの画像生成を披露しました。会議で発表された自動運転やリアルグラフィックスなど様々な技術の中で最も印象に残る技術の一つだったと言えるでしょう。

発表会にて、まず彼らはインターフェースに「beach」と入力しました。するとビーチの絵のようなものがモニター上に現れました。この時、絵には雲が描かれていました。そこで次に「beach – clouds(ビーチ マイナス クラウド)」と入力すると、青空に雲ひとつないビーチの絵が新たに浮かび上がりました。最後に「sunset beach – clouds」と入力すると、夕日でオレンジ色に照らされたビーチが出現したのです。
この研究に用いられている“ニューラルネットワーク”とは機械学習技術の一つであり、人間の脳機能の特性をシミュレーションによってPC上に再現することを目的とした数学モデルのことです。
ニューラルネットワークの概要図:
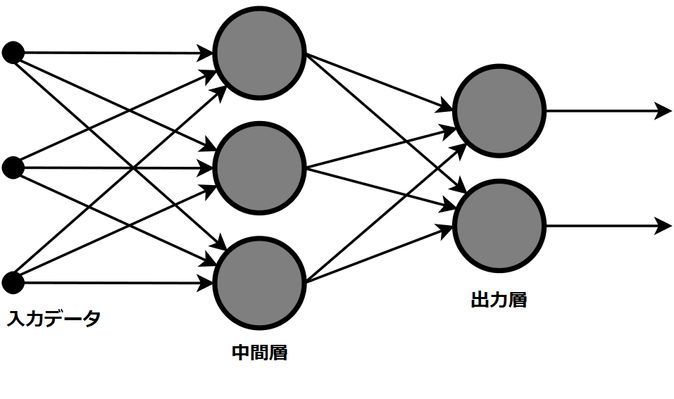
教師データによる学習を行うことで、入力データが最適解(正解)に近づくようニューラルネットを教育。学習によって得た知識を中間層に蓄えていくことで、ニューラルネットは最適解を出力するように学習していく (画像参照元: ニューラルネットワーク Wikipedia)。
Facebookは、何百万という画像を用いて、特定の単語と画像を結びつけるためにニューラルネットワークを訓練させていると考えられます。ここで重要な点は、画像内の個々の要素(前述の例だと雲や夕日)を認識し、自然言語インターフェースを介して動的にそれらを取り外して交換できているという点です。これは大きなブレークスルーだと言えるでしょう。
今回の発表では2次元画像のみでしたが、これが3D用に実装された場合、テキスト記述から3Dオブジェクトの生成ができるということはVRコンテンツの生成をより高速化することができ、非常に有用であると言えます。
もっとも3Dへの応用は簡単ではありません。2D画像とは異なり、ニューラルネットワークの学習に用いる十分な3Dオブジェクト資源がネット上に存在しないからです。しかし今後VRとARが普及するにつれてネット上の3Dオブジェクト資源が増えることが予想されるため、不可能ではないかもしれません。
(関連記事)
Facebook、360度動画をVRでストリーミング再生時に効率的・高品質な描画技術を導入
(参考)
New Facebook AI Research Could Generate Dynamic Virtual Worlds(英語)
http://uploadvr.com/facebook-neural-ai/









{kind=link}