Appleがシーンを説明する文章や画像から3次元のシーンの映像を生成する技術「GAUDI」を発表しました。「GAUDI」はカメラを移動させながら複雑でリアルな3次元のシーンの映像を生成できる機械学習のモデルです。建築家のアントニ・ガウディにちなんで「GAUDI」と命名されました。

文章から3Dシーンの画像を生成
これまでも、文章から画像や3次元の物体を生成する研究が世界中で行われています。例えばAIの研究をしているOpenAIが開発した「DALL・E 2」と呼ばれるモデルでは、入力した文章が表す物体やシーンの画像を生成できます(筆者のアイコン画像は「DALL・E 2」の派生モデルを使って「HMDを使っている可愛いクマ」という文章から生成した画像です)。また、Googleの「Dream Field」は入力文章から物体の3Dモデルを生成できます。
「GAUDI」では、入力された文章から3次元シーンを移動する映像を生成できます、例えば「Go up stairs(階段を上がる)」という文章を入力すると階段を上がっていくカメラワークの映像を生成できます(アイキャッチ画像の中央列の画像)。「Walk out of the bedroom and into the living room(寝室から出てリビングルームに入る)」のように、カメラの経路を文章で指示することもできます。また、画像を入力して、入力画像に似た景色の映像を生成したり、入力なしでランダムに3次元シーンの映像を生成することもできます。
3つのネットワークで3Dシーンの描画を実現
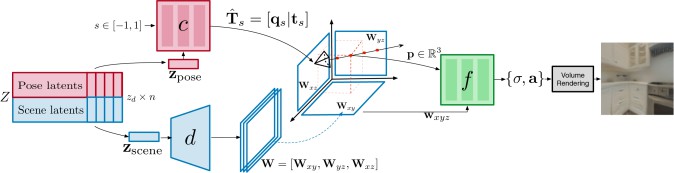
「GAUDI」は3つのネットワークで構成される3次元のシーンの映像を生成するモデルです。1つ目はカメラの軌跡(姿勢)を予測する「カメラ姿勢デコーダネットワークc」、2つ目は3次元シーンを予測する「シーンデコーダネットワークd」、3つ目は前記2つのネットワークから得られた3次元シーンとカメラ位置と姿勢を元に3次元空間中の各位置の色や透明度の情報を予測する「ラディアンスフィールドデコーダネットワークf」です。3つ目のネットワークから出力された情報を元に3次元シーンの画像を描画します。
AIが3次元空間を理解し、創り出すために必要不可欠な研究
GAUDIで生成した映像は解像度が低く、アーティファクトが発生するなど、映像品質は高くありません。しかしながら、この技術は画像からカメラの位置や向きを推定するSLAM技術、3Dコンテンツ作成、モデルベースの強化学習や計画に利用できるとしています。
また、Appleは3次元シーンを生成するモデルの研究は、AIが3次元空間を理解し、創り出すために必要不可欠な研究としています。今後AIが3次元を理解し、カメラで現実の空間を認識するだけでなく、文章や自分で撮影した写真をもとにメタバースで利用できる3次元空間を自動的に創り出すことが期待されます。
今後「GAUDI」のソースコードは公開される予定です。








