Metaは4月5日、新しい機械学習モデル「Segment Anything Model(SAM)」を発表しました。動画像の物体検出が、手間のかかる前処理や追加学習なしで、リアルタイムで正確に行えるとしています。同社はこの汎用モデルと査読前論文、マスキング済みの学習データセットを公表。この研究分野の発展を加速させたい模様です。

(出所:Meta)
SAMを用いたオブジェクトセグメンテーションとは
Metaが今回発表した「Segment Anything Model(SAM)」は、コンピュータービジョン(機械学習による画像認識、物体検出)の一分野である「オブジェクトセグメンテーション(対象区画)」を行う機械学習モデルです。オブジェクトセグメンテーションとは、撮影デバイスで取得された動画像に映る個々の物体を認識し、その対象を周辺情報から切り出すタスクを指します。
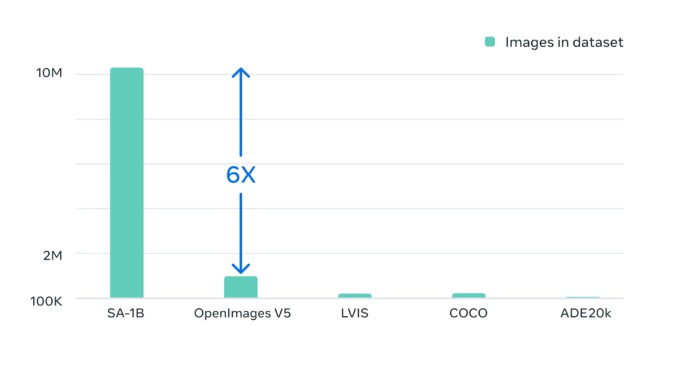
SAMは、1,100万枚の画像データを活用してこのプロセスを高速・軽量化。(高性能GPUを使えば)1秒未満で高精度な物体検出を可能にしました。同社は、この機械学習モデルの査読前論文、10億超のマスキングが施されたトレーニングデータをセットで公開しました。
AR分野の重要技術だが、研究開発に膨大なコストが必要だった
AR分野にとって、オブジェクトセグメンテーションは非常に重要な技術です。例えば、現実空間にあるモニターの左右にARグラスで2つの仮想モニターを表示したいとき、本物のモニターがどれか判別できなければ、仮想モニターを適切に表示できません。
とはいえ、モニター(現物)にはさまざまな形・大きさ・色があります。光の反射や遮蔽物も考慮しなければ、そのモニターがモニターだと正しく認識するのは難しいのです。
これまでも、動画像に映ったモノを識別する研究は行われてきました。これらの研究では、画像認識アルゴリズムに動画像データを学習させ、対象物の「見落とし(未検出)や見まちがい(誤検出)をなくす」ことを目標としていました。
しかしどれほど精度を改善しても、そのアルゴリズムにとって未知の対象物は存在します。アルゴリズムの性能を高めるには、さまざまな物体の切り出しをくり返し行うか、大量の画像データを用意して膨大なラベル付け(アノテーション)を施すなど、膨大なコストをかける必要がありました。
大規模な事前学習で「モノの概念を理解した」と言えるほどの汎用性に
そこでMetaは、今までにない規模の事前学習データを用意し、「オブジェクトとは何か」という”概念”を学習したと言えるほど、十分に汎用性の高いモデルを開発。同社によると「1,100万枚の画像に11億区分のマスキングを施した」ことで、追加学習なしでも「水中写真や細胞顕微鏡検査」といった新しい分野にも応用できるとしています。
(出所:Meta)
(編注:MetaはGoogleの大規模画像データセット「OpenImages V5」(2019)などと比べて6倍の画像を用いたとしていますが、2022年に発表された「Open Images V7」は190万枚の画像を用いており、この主張にはやや誇張があります。)
(出所:Meta)
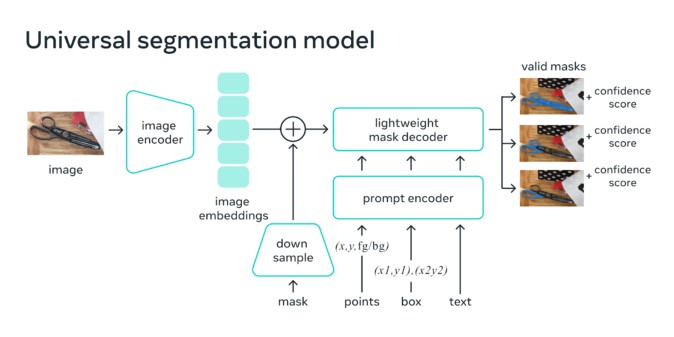
Segment Anything Model(SAM)の特徴は、ユーザーが「どの瞬間に何を検出させるのか」を3種類のプロンプト(対象点、矩形、テキスト)とその組み合わせで指定できる点です。SAMは、与えられた画像(の埋め込みベクトル)とプロンプトを変換・結合し、軽量化されたマスキング情報(対象物の形状)との当てはまりを予測します。この処理を1秒未満で行うことで、ユーザーはWebブラウザで動画像をクリックするだけで、あいまいなセグメンテーションを回避し、物体の境界を指定できます。
(編注:ごく簡単にいえば、「シルエットを見ただけで、どの芸能人が出演するか当てる」ような処理を瞬時に行っています。)
セグメンテーションの民主化を目指す
研究チームは、AR/VRデバイスで用いられるアイトラッキング技術と組み合わせることで、将来には「ユーザーの視線に合わせて認識対象を選び、3D空間へ『持っていく』ことが可能になる」としています。

(出所:Meta)
Metaは、SAMをオープンソースライセンス(Apache 2.0)でGitHubに公開。学習用データセット「SA-1B」も限定ライセンスで公開しています。
同社は、「本プロジェクトを公開することで、セグメンテーションの民主化を目指しています。私たちの研究とデータセットを共有することで、セグメンテーションと画像と動画の理解に関する研究をさらに加速させたいと考えています」とコメントしています。
(参考)Meta、Road to VR
(執筆:パンみみこ、編集:笠井康平)








