人の目は、三次元空間の認識を自然に行うことができます。しかしコンピュータービジョンで2D画像から3Dのイメージを構築するのは、そう容易ではありません。
グーグルはディープラーニングに基づくアプローチにより、動くカメラで動く人物を撮影した動画からデプスマップを作成し、コンテンツ作成に活用する手法を発表しました。
デプスマップとは
3Dイメージ作成に必要となるのがデプスマップです。3次元空間の奥行きのデータで、カメラから対象までの距離を推定します。
3Dイメージ生成で特に困難なケースは、対象とカメラの両方が動いている場合です。なぜなら通常三次元イメージ構築には、triangulation(三角測量)の手法が用いられているためです。この方法は、対象が少なくとも2つの視点から同時に捉えられる、という仮定に基づいています。そしてこの条件を満足するには、複数のカメラを連結するか、静止した場面を1台のカメラを動かし撮影するか、が必要です。
結果、該当しないシーンでは動く物体は除外されるという自体が発生します。
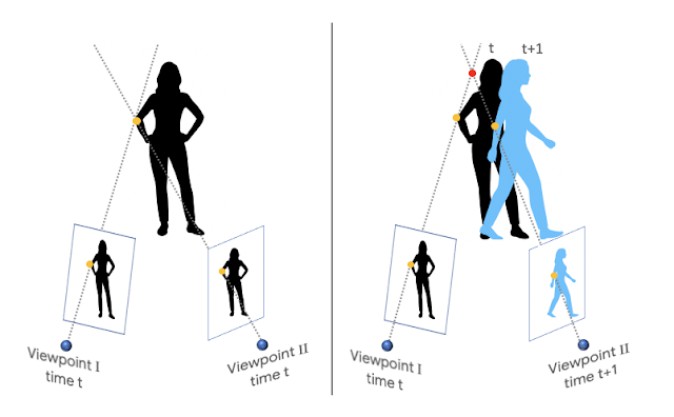
動く人物を扱う手法
グーグルはディープラーニングに基づくアプローチにより、この課題解決に取り組みました。カメラも対象も動く動画から、デプスマップを作成するのです。
撮影の対象物としては、人物に焦点を当てました。ARや3D動画において、人は興味深いターゲットであるからだ、とグーグルは理由を説明します。
取組を進めるにあたり必要なものが、動くカメラで撮影した自然なシーンと、その正確なデプスマップです。
今回グーグルが深層学習に用いたのは、YouTubeにあげられた動画です。人々が様々なポーズでマネキンのように静止し、カメラがその間を進みながら情景を撮影している、という“マネキンチャレンジ”のムービーです。対象が静止してカメラのみ動いている、正確なデプスマップを得られるといった観点から条件に合致しています。グーグルはマネキンチャレンジの動画を約2,000本集め、動くカメラで撮影した「静止した」人間のデプスデータを収集しました。
次に必要なのは、動くカメラで撮影した動く人間の動画を処理する、という目標への橋渡しでした。動画の各シーンごとにそれぞれ深度を推定する、といった手法が考えられます。
グーグルはさらにアプローチの改善を進め、単独のシーン別でなく多数のフレームを同時に用いることとしました。具体的には、動画内のフレーム同士のオプティカルフロー(※)を計算。カメラの動きによる影響を除き、まずは対象が静止した状態の、第一段階のデプスマップを作成します。
(※オプティカルフロー:二枚以上の連続する画像を用いて、その画像内で共通して写っている部分などから動作や移動する方向を推定しベクトルで表したもの)
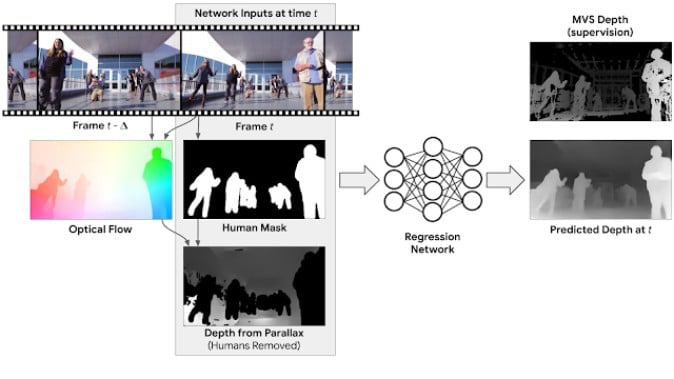
そしてこのデプスマップの中で、人物の部分をマスキング。こうして、RGBイメージ、マスキングされた人物、そしてデプスマップ、から構成されるデータを生成します。最後にディープラーニングにより、人物が映る部分のデプスデータを補足、その他の深度情報も修正します。画像の学習を繰り返すことで、カメラと対象双方が動いている動画からのデプスマップを構築可能になる、ということです。
このように深度を推定して作成したのが、下記に掲載する動画です。右下の「Ours」と題したものが、今回グーグルの手法を用いたものとなります。

デプスマップの用途は?
では、このデプスマップの活用法はどのようなものがあるでしょうか。グーグルは、用途の例として焦点ぼけの合成を挙げます。下図のように、普通の動画とデプスマップを用いて、周囲をぼかしたイメージを生成できるというものです。

その他にも、単眼カメラで撮影した動画からステレオビデオの作成、ムービーへのCGを合成、といった応用が期待できます。グーグルによれば、あるシーンで隠れてしまっている部分を、デプスマップの活用によって他のフレームの情報から補うことも可能とのこと。3Dイメージの構築だけでなく、コンテンツ作成における幅広い利用方法があるとしています。
(参考)Google AI Blog








