フェイスブックは、人間の全身を対象とするモバイル向けARアプリケーションの開発に取り組んでいることを明らかにしています。スマートフォンなどのカメラを使って、手軽に全身のモーションキャプチャをしてアバターなどに変えて表示することができるようになる可能性があります。

現在、リアルタイムの顔トラッカーを使用することでカメラ機能を使って顔にメイクを追加したり、アバターに置き換えることができます。モーションキャプチャにより、自分の全身をアバターに置き換えることができるようになるとFacebook社のブログで公開しています。
困難なモーションキャプチャを容易に
身体全体をアバターと置き換えるには、体の動きをリアルタイムで正確に検出し、追従させる必要があります。身体の動きを検出するためには、ポーズや個人差によって大きく変わり、追従が非常に困難です。
PCとモーションキャプチャデバイスを組み合わせる方法が現在は主流です。また、スマートフォンでモーションキャプチャを実現する技術には、「Notch」が登場しています。Notchが提供する技術は身体にセンサーを取り付けてのモーションキャプチャですが、フェイスブックが開発中の技術はスマートフォンのカメラのみを使い、画像処理でモーションキャプチャを行う点が大きく異なります。

たとえば、対象者が座ったり、歩いたり、走っている可能性や長いコートを着ている可能性もあり、こういった要因が身体を追従するシステムを困難にしています。
フェイスブックのブログによると、体のポーズを正確に検出し、人を追従する新しい技術を開発したとしています。現在、研究段階ですが、数メガバイトの容量となっており、リアルタイムにスマートフォンで実行することができるとのこと。

Mask R-CNN2Goを使用した検出
今回の身体の検出には、深層学習アルゴリズムMask R-CNNを改良したMask R-CNN2Goを使用しているとのことです。このMask R-CNNは、セマンティックセグメンテーション(画像の中のオブジェクトを個別に検出する)分野で現在、最も注目されているアルゴリズムです。
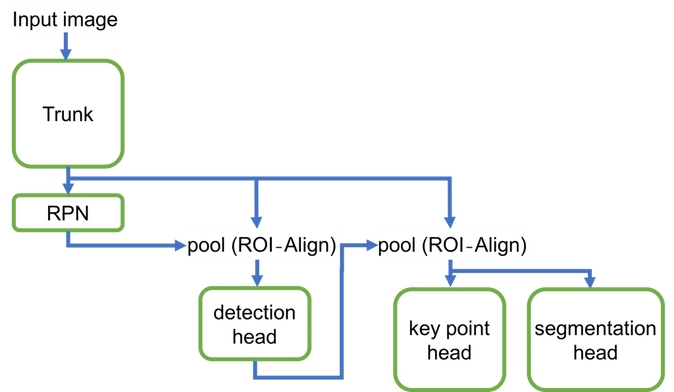
Mask R-CNN2Goは次の5つの要素で構成されています。
- Trunk model:複数の畳み込み層を含み、入力画像から特徴点を抽出します。
- Region proposal network(RPN):事前に定義されたスケールとアスペクト比での候補がないかを出力します。ROI-Align層に、出力した各バウンディングボックスから特徴を抽出し、Detection headに渡します。
- Detection head :畳み込み層、プーリング層、全結合層から成っています。候補となったバウンディングボックス事にオブジェクトが人であるかどうかを判別するほか、バウンディングボックスの座標を精細化し、画像内の各人物の境界を設定します。
- Key point head:各人物の境界と2つめのROI-Align層を使用し、特徴を抽出します。抽出した特徴はSegmentation headに送られます。
- Segmentation head:抽出した特徴から、最終座標を生成するために使用されます。
モバイルデバイス向けに軽量化されたモデル
深層学習を用いたリアルタイム処理には通常、高い計算能力を持つGPUが必要となりますが、モバイルデバイスの計算能力や容量は限られたものとなっています。基となったMask R-CNNはResidual Network(ResNet)と呼ばれる、最大1000層以上の深いニューラルネットワークを使用しており、これはモバイルデバイスで使用するにはとても遅くなってしまいます。モバイルデバイス用のコンピュータービジョンモデルを開発することは非常に困難です。必要メモリが少なく、高速で、正確である必要があります。
そこでFacebook AIカメラチームが開発したのは、「モバイルデバイス向けに最適化された非常に効率的なモデル」とのこと。今後も効率的なモデルなどを探求し続けると述べており、バッテリーと、計算能力の両方を併せ持つモデルについて検討していくとのことです。
(参考)
Enabling full body AR with Mask R-CNN2Go/facebook research(英語)
https://research.fb.com/enabling-full-body-ar-with-mask-r-cnn2go/
Facebook Preparing New Wave of Full Body AR Camera Lenses/VRSCOUT(英語)
https://vrscout.com/news/facebook-full-body-ar-camera-lenses/








